BLIS: Evolving llm-d at Simulation Speed










llm-d is built for distributed LLM serving: routing, flow control, placement, auto-scaling, disaggregation decisions, engine configuration, all happening at once. That makes it powerful, but also hard to evolve. A small policy change in admission, routing, batching, or autoscaling can change latency, throughput, and inference cost in unexpected ways.
The only honest way to know is to test. But testing every idea on real GPU clusters is slow and expensive.
BLIS solves this problem.
Why distributed serving is hard
Imagine 500 requests per second hitting your cluster. Here is what has to happen:
- The gateway decides who gets in and who waits.
- The router picks which vLLM instance handles each request. It looks at prefix cache hits, queue depth, and KV use.
- Each instance decides which requests to batch together right now.
- The KV cache has to find room. Old blocks may need to make space.
- The autoscaler watches load and brings new instances up if needed.
- Maybe prefill and decode should run on different pools of GPUs.
Every one of these is a knob. They interact. No one can predict the result on paper. BLIS models all of them.
The problem in one chart
The same policy-change question can be answered in two ways: run it on a real cluster, or simulate it first. Cluster experiments can take days to configure and tune, while simulation runs on your laptop within a few minutes.
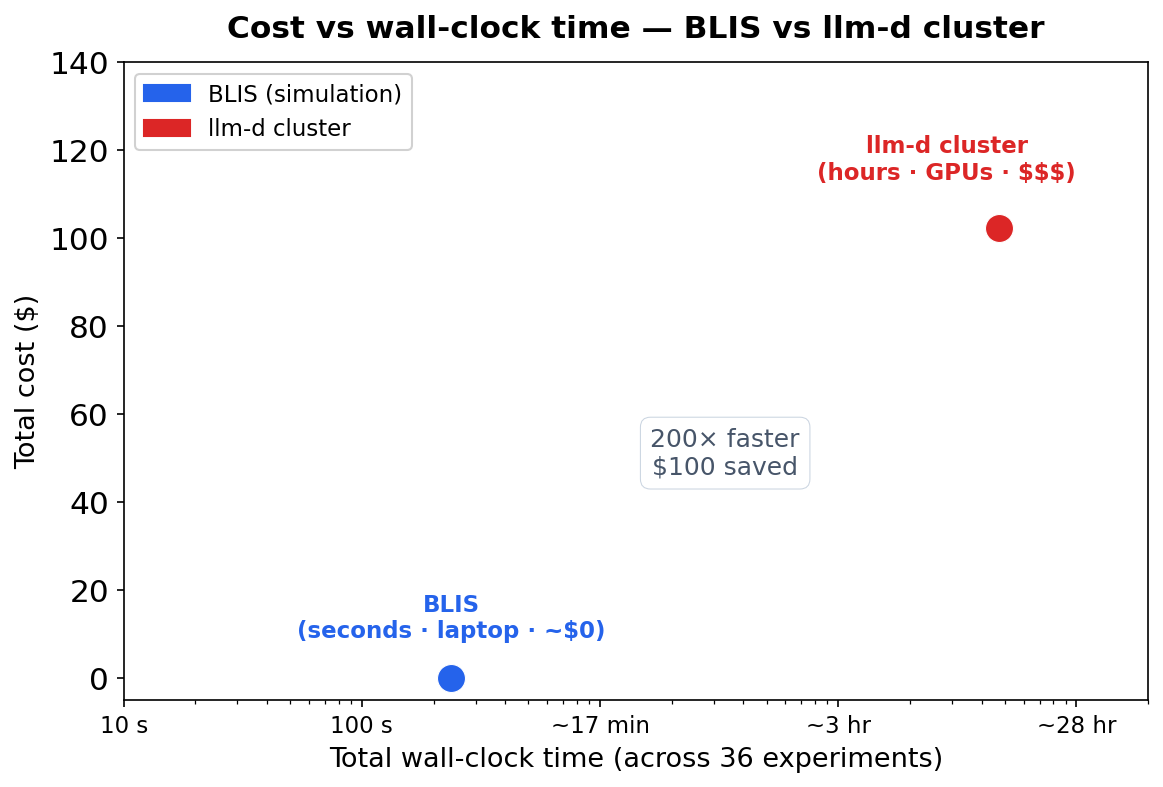
Same question. Very different cost.
What is BLIS?
In essence, BLIS simulates llm-d. It mirrors llm-d's behavior: admission, routing, scheduling, KV cache, batching, and autoscaling — minus the GPUs.
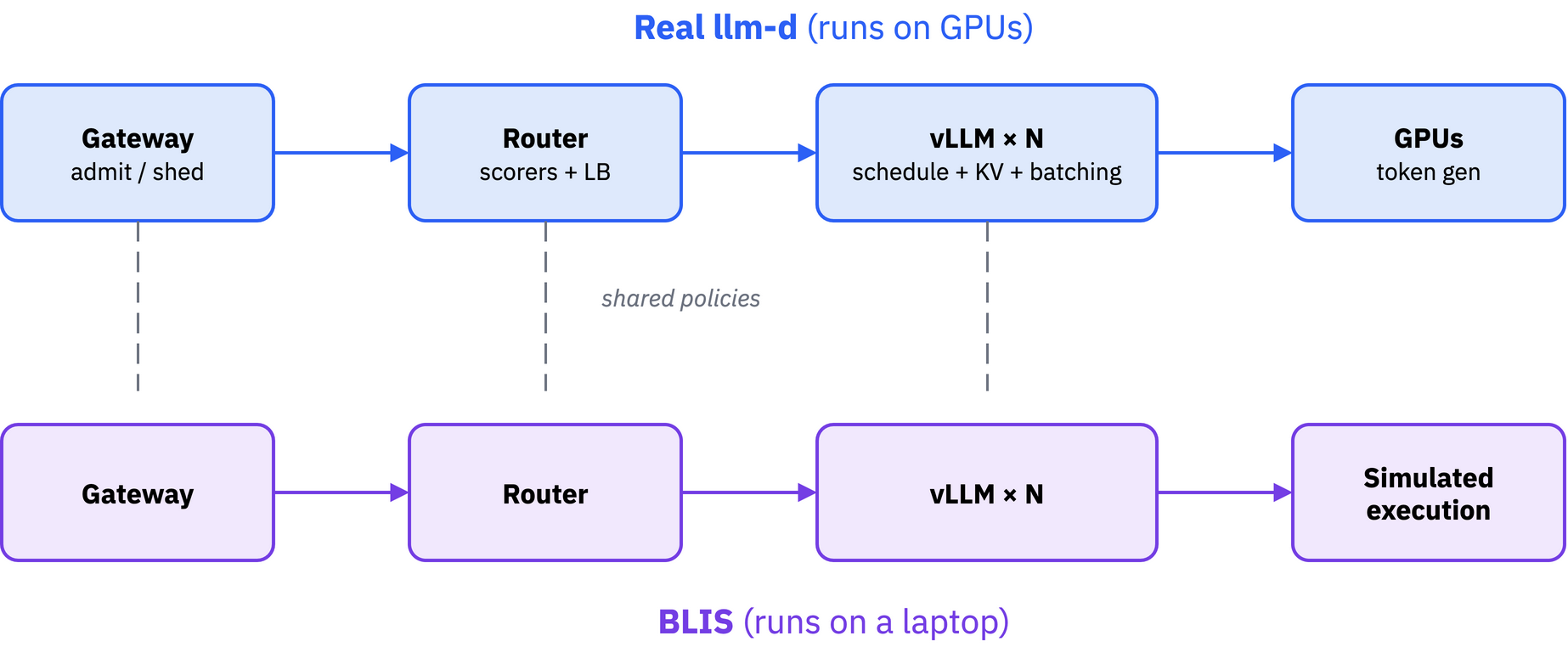
BLIS is not meant to replace real clusters. It offers an opportunity for fast and cheap experimentation to identify the most promising directions for targeted cluster runs.
How can BLIS be useful without GPUs? It is a discrete-event simulator with pluggable parts that mimic the physics of a single vLLM instance and the dynamics of llm-d's distributed serving. Each prefill and decode step is estimated by a performance model fit to real GPU measurements. That is enough to reproduce the queueing, batching, and latency a real cluster would see: no weights loaded, no tensors moved.
What BLIS gives you
- Fast and cheap. Seconds per run. No GPUs.
- Deterministic. Same input, same output, every time.
- Pluggable. Drop in a new admission rule, scorer, or autoscaler. BLIS runs it as llm-d would.
- High-fidelity. Mimics the real llm-d cluster closely and yields realistic latency and throughput metrics.
What BLIS unlocks
BLIS has two jobs. It helps llm-d evolve faster, and it helps users plan deployments before spending GPU time. Let's start with the bigger one.
AI-native evolution of llm-d
AI-native evolution means agents help propose, test, and improve policies (or new algorithms), with real clusters used to validate only the most promising ideas.
The idea is simple. BLIS is the inner loop. Real llm-d is the outer loop. Developers can connect BLIS to any policy-search workflow they choose, whether that is a human-driven sweep, a custom optimizer, or an AI-agent system.
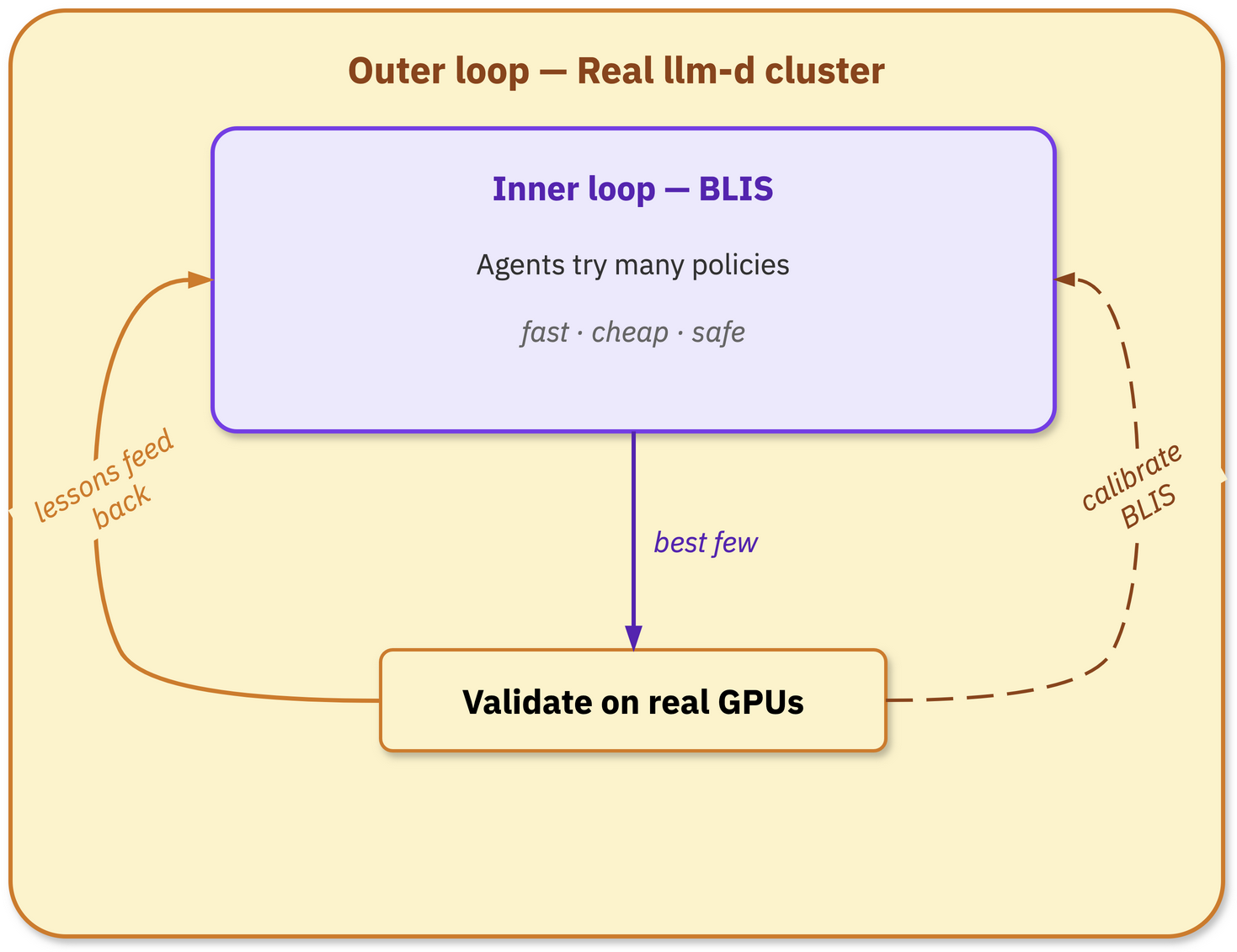
In AI-native evolution, agents try many policies (or algorithms) in BLIS. The best ones go to a real cluster for validation. Lessons fold back into the next round of exploration. This loop is starting to deliver measurable improvements to llm-d.
From latency cliffs to graceful admission control
Under overload, default llm-d admission control can behave like a cliff. Things look fine, then suddenly they don't. Using the AI-native loop with agents exploring policies inside BLIS, we found a smooth, parameter-free shedder. On 4×H100, TTFT p90 was about 30× faster in the tail for critical requests. Sheddable traffic gets dropped early, so the queue never piles up.
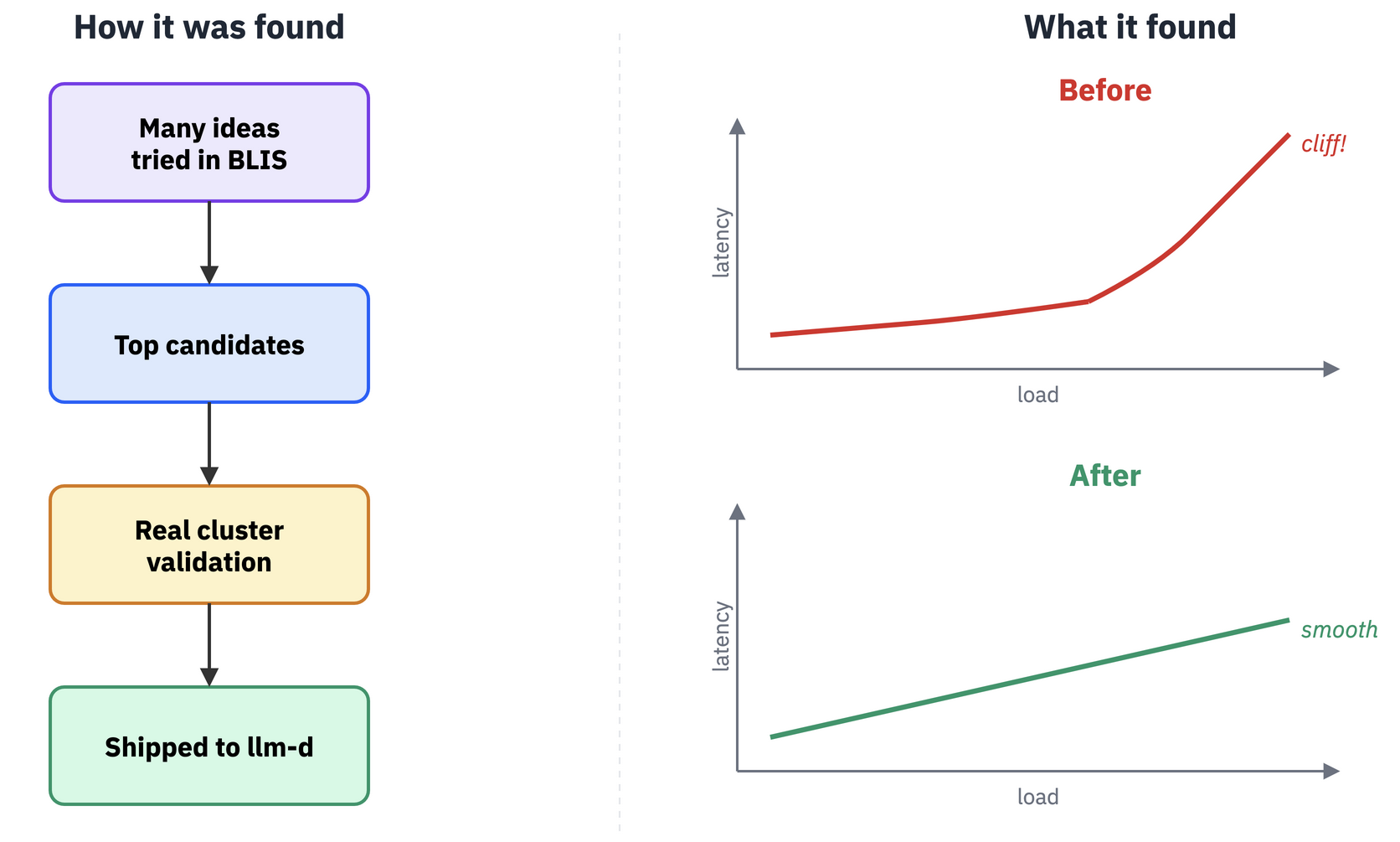
For the full story, see our earlier post on the admission controller loop.
When to disaggregate prefill and decode
We used BLIS to study a multitude of heuristic policies, ranging from always local, always disaggregate, stationary randomized, and a dynamic policy called Drift Plus Penalty (DPP), inspired by Lyapunov optimization. We analyzed their performance under various workloads and arrival processes and observed regimes where each policy stands out.
The figure below shows a subset of results we obtained with BLIS. The Empirical DPP (EDPP) outperforms the prefix cache-based P/D decider currently in llm-d by 2-20x on TTFT. We've even seen the llm-d decider as actively harmful on long-context workloads like code-gen.
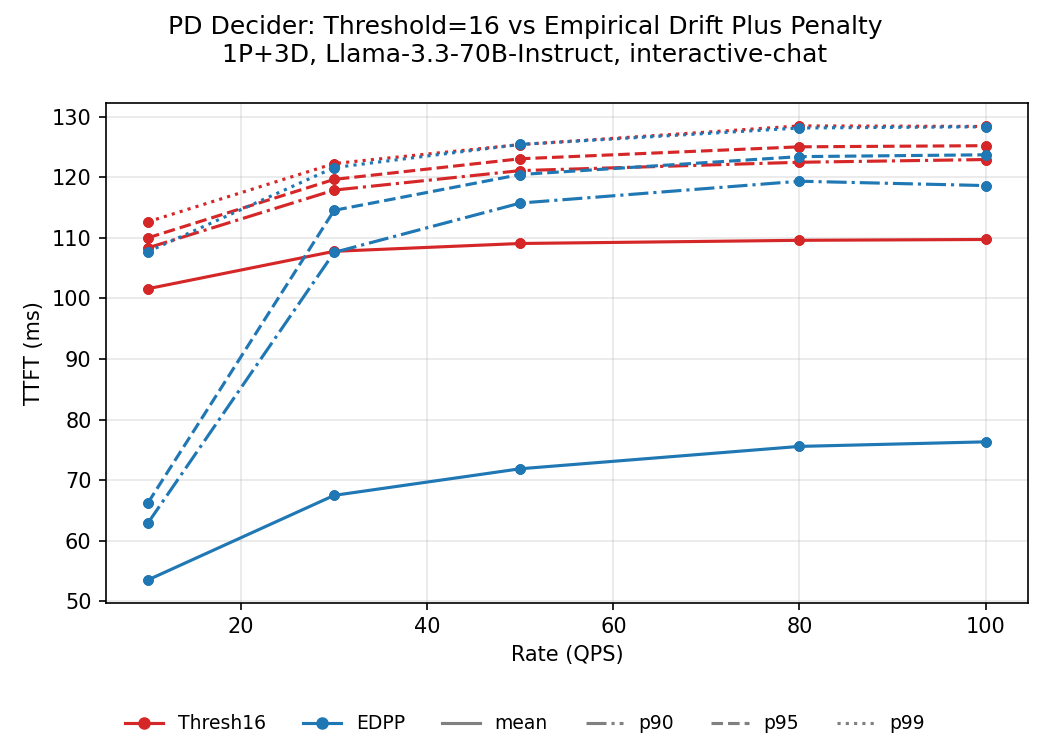
These are the kind of results that are expensive to find on real GPUs but natural to find with BLIS.
Capacity planning
Before you deploy any LLMs for any purpose, you need answers:
- How many GPUs? Which GPU type?
- What configurations meet the SLO?
- Which router knobs — scorer weights, prefix-cache priority, load-balance settings?
- Which vLLM knobs — tensor parallelism, chunk size, batch limits?
Each of these used to mean a real-cluster experiment. With BLIS, it's a sweep that runs in seconds per config. You can scan a hundred settings before lunch and walk into the deployment meeting with a much smaller, better-ranked set of choices.
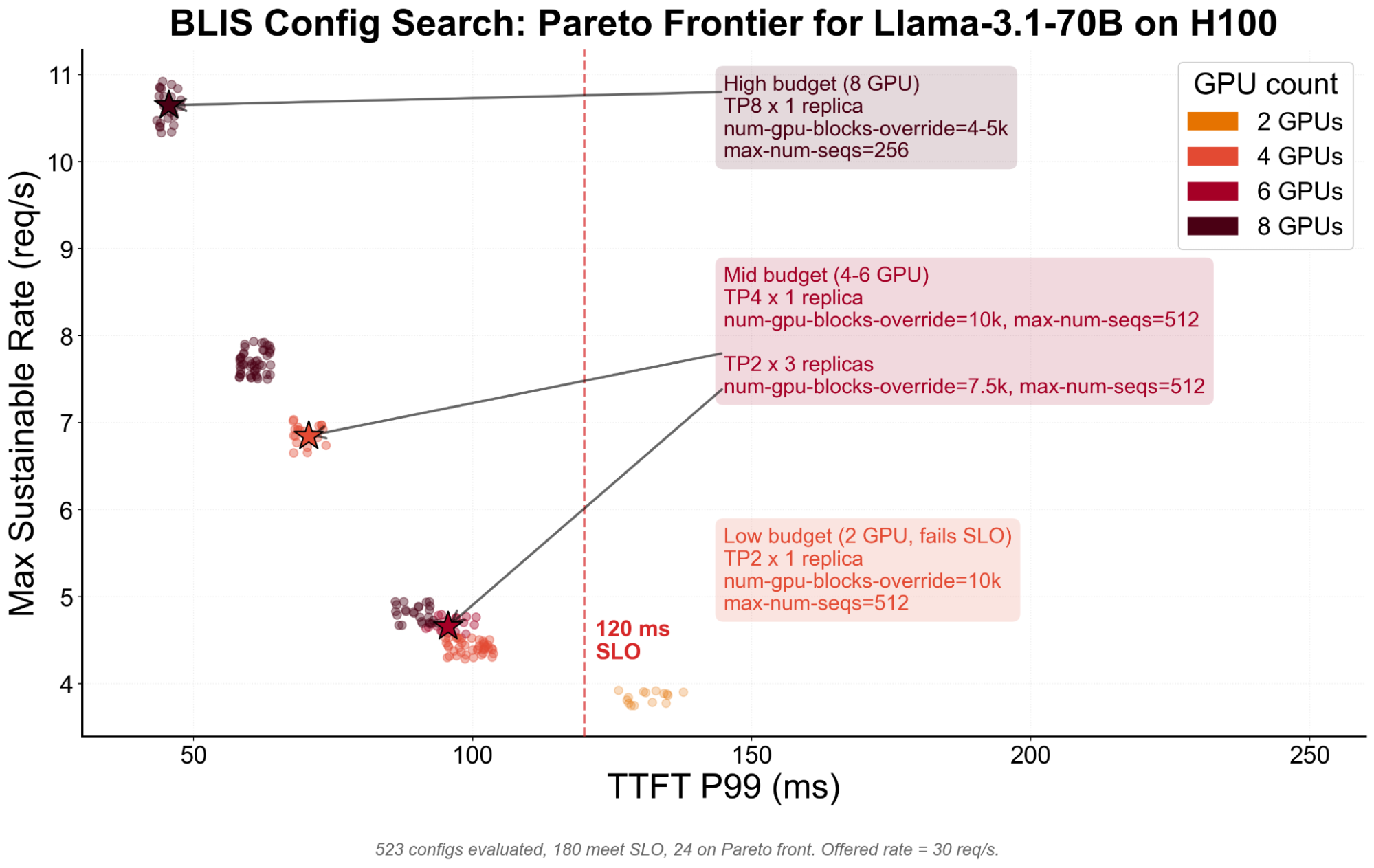
Every dot is a BLIS evaluated configuration. The best throughput you can achieve at any given GPU budget while meeting your latency target. Up-and-to-the-left is better (fast and high-throughput). The dashed vertical represents a TTFT SLO we need to meet, and only points to the left represent configurations meeting that SLO. The starred configs represent the best-performing configurations for each budget tier in terms of GPU count.
Using multi-objective search, we can discover throughput, latency, and cost tradeoffs easily with BLIS. This experience gives you the ability to deploy only what you feel most confident about.
llm-d-planner, the deployment-recommendation tool for llm-d, is planned to consume BLIS output to power exactly this kind of sizing and policy advice.
Why this matters
Without BLIS, llm-d evolves only as fast as people can run real-cluster experiments. Every new policy idea competes for scarce GPU time, and even routine development can become slow, expensive, and hard to iterate on.
With BLIS, llm-d developers get a fast, cheap inner loop before they touch a GPU. They can test routing changes, admission policies, batching behavior, prefill/decode decisions, and capacity assumptions in simulation, then reserve real clusters for the few ideas worth validating.
That matters whether the next idea comes from a human developer, an AI agent, or both. BLIS helps tame GPU scarcity for everyday llm-d development, while also enabling the AI-native loop: agents can explore many more policies than humans could test manually, and real clusters validate the best ones.
That is the shift: llm-d can evolve as fast as developers and agents can think, simulate, and learn.
Where to next
- BLIS: inference-sim.github.io/inference-sim
- Earlier reads:
- The admission controller story in full: From simulation to production
- The upcoming BLIS proposal for llm-d