BLIS: Evolving llm-d at Simulation Speed
· 8 min read










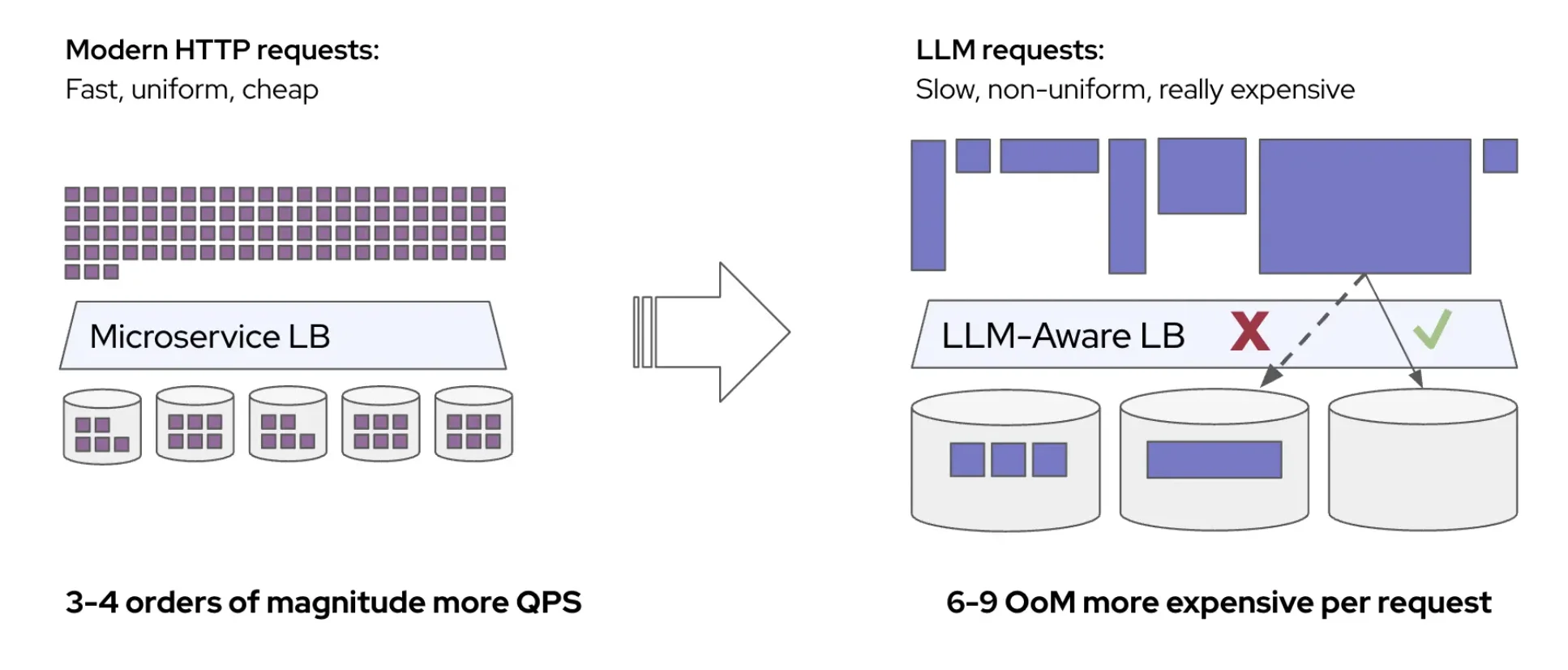
llm-d is built for distributed LLM serving: routing, flow control, placement, auto-scaling, disaggregation decisions, engine configuration, all happening at once. That makes it powerful, but also hard to evolve. A small policy change in admission, routing, batching, or autoscaling can change latency, throughput, and inference cost in unexpected ways.
The only honest way to know is to test. But testing every idea on real GPU clusters is slow and expensive.
BLIS solves this problem.